An OMNY Health Study on Severity Measure Extraction in Respiratory Care
Understanding disease severity is essential to supporting treatment decisions, yet many critical severity metrics—especially in respiratory conditions—are often buried in unstructured EHR notes. At ISPOR 2025, OMNY Health presented findings on how large language models (LLMs) can accurately extract FEV1/FVC scores, a core pulmonary function test (PFT) metric, directly from free-text clinical notes.
Why It Matters
Clinical measures like FEV1/FVC are pivotal in evaluating lung function and diagnosing COPD and asthma. However, these measures are not consistently captured in structured EHR fields, making them difficult to access at scale. OMNY Health’s study explored whether retrieval-augmented LLMs could help close that gap—automating severity extraction while preserving accuracy.
Study Overview
OMNY Health researchers sampled 50 random note excerpts containing the phrase “FEV1/FVC” from the OMNY Health platform and categorized them as:
- Simple (S): One FEV1/FVC score present
- No Value (NV): No score provided
- Complex (C): Multiple scores present
OMNY Health researchers tested two Gemini LLMs (Flash and Pro) using a structured prompt and evaluated:
- Accuracy in correct extraction
- Hallucination rate (false outputs when no score existed)
- Latency (processing time in slot milliseconds)
Key Findings
1. High Accuracy in Simple Notes
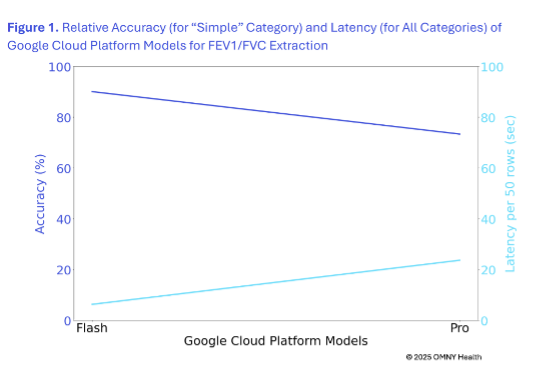
Flash extracted FEV1/FVC scores with 90% accuracy, outperforming Pro (73.3%).
2. No Hallucinations in NV Notes
Neither model generated phantom data when no score was present.
3. Pro Recognized Complex Context Better
While Flash returned one of the multiple scores, Pro acknowledged the complexity—useful for nuanced documentation.
4. Flash Was Faster
Flash processed data using 6,210 slot milliseconds versus Pro’s 23,576—offering speed advantages for scale.
Example Outputs
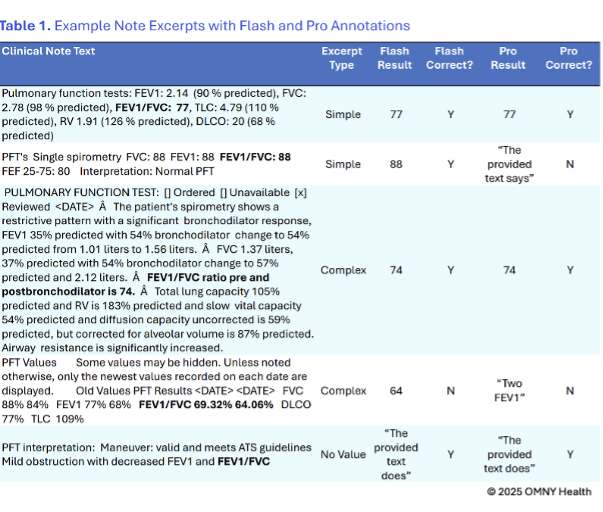
Performance Snapshot
What’s Next
This study highlights how LLMs can reliably extract clinical severity measures from real-world EHR data. Moving forward, the team plans to evaluate performance across more complex note structures, investigate how interpretability and robustness vary by model, and assess the trade-offs between cost, speed, and depth of output. The long-term vision is to expand this approach to other therapeutic areas where structured fields fall short—enabling deeper, more scalable evidence generation.