By Lawrence Rasouliyan, Amanda G. Althoff, and Danae A. Black | OMNY Health
Understanding the Role of Lung Function in Asthma Management
Lung function monitoring is important in the management of asthma, and it provides valuable information to clinicians on disease control and patient response.
Pulmonary function tests are common tests conducted in clinical settings, yet they are infrequently documented as measurements in free-text notes or tabulated sources of real-world data.
Meanwhile, disease severity and acute exacerbations are usually available based on the diagnosis codes such as the ICD-10.
However, the association between coded severity and measured indices of lung function has not been well characterized in routine clinical care data on a large scale.
This gap was filled by our team at OMNY Health, which analyzed the relationship of lung function measures with severity and exacerbation status in subjects with persistent asthma.
Study Overview
Using electronic health record (EHR) data from 2017 to 2024, we analyzed information from three integrated delivery networks included in the OMNY Health real-world data platform.
Patients were included if they had an ICD-10 code for persistent asthma classified as mild, moderate, or severe—either with or without an acute exacerbation. The relevant ICD-10 codes used for classification are shown below.

To be included, patients also needed at least one documented lung function measurement—specifically, forced expiratory volume in one second (FEV₁) percent predicted (pp), forced vital capacity (FVC) pp, or FEV₁/FVC pp—associated with an asthma-related encounter.
Key Findings
Out of approximately one million patients identified with an asthma ICD-10 code indicating severity and exacerbation status, 14,003 patients (across 31,463 encounters) had corresponding lung function data available.
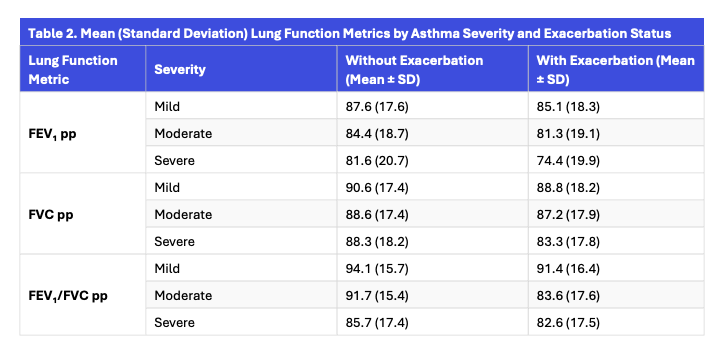
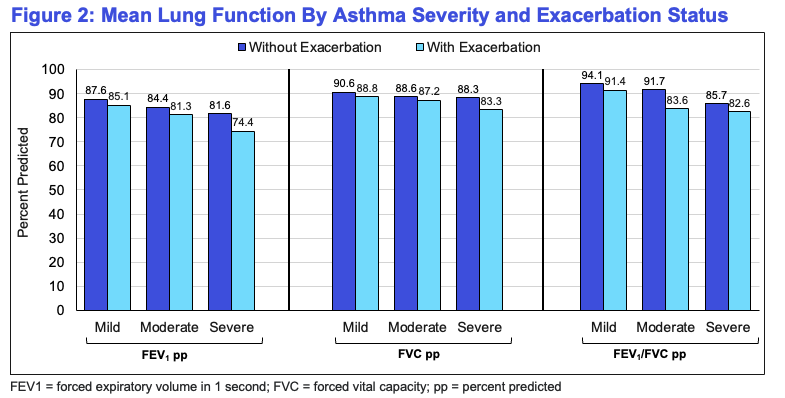
Across all severities, lung function metrics declined with increasing asthma severity, and patients experiencing exacerbations consistently had lower lung function compared to those without exacerbations.
What the Data Suggests
Findings have shown a considerable decrease in mean lung function values because asthma severity increased—regardless of exacerbation status.
Patients experiencing exacerbations had consistently lower FEV₁, FVC, and FEV₁/FVC metrics as compared to the ones with no exacerbations.
Most interestingly, when we compared ICD-10–coded severity to typical clinical cutoffs for lung function, the correspondence was not strong enough.
This undoubtedly suggests that ICD-10 coding alone may not fully capture physiological severity, emphasizing the importance of integrating structured and unstructured lung function data into real-world datasets.
Why It Matters
By leveraging structured EHR data, this study highlights the potential to better understand asthma progression and treatment outcomes across real-world populations.
The results reinforce the value of using lung function metrics—not just diagnosis codes—to assess disease burden and guide more precise asthma management strategies.
References
- Levy ML, et al. NPJ Prim Care Respir Med. 2023;33(1):7.
- Firoozi F, et al. Thorax. 2007;62(7):581–7.
- Gronkiewicz C, et al. Chest. 2015;147(4):1152–1160.
- Xie F, et al. JMIR AI. 2025;4:e69132.
© 2025 OMNY Health