Depression and anxiety are common conditions associated with a range of physical health outcomes, including changes in body weight. However, risk is not uniform across all patients. Two individuals with the same diagnosis may have very different symptom profiles and very different metabolic risks.
This symptom variability raises an important question: Can routinely collected symptom data help identify patients who may be at higher risk for clinically meaningful weight outcomes?
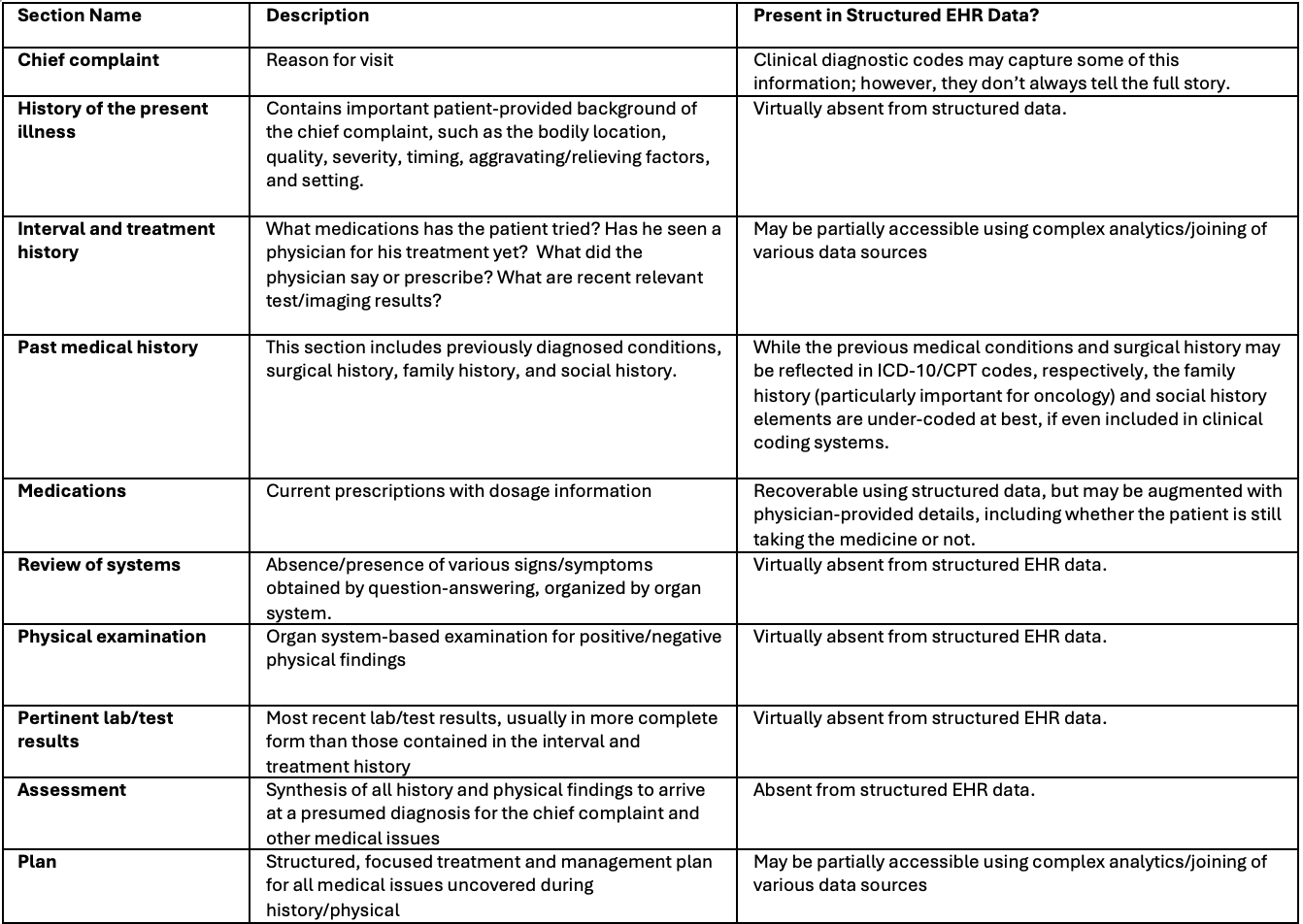
Many real-world data sources capture diagnoses, procedures, and medications, but few contain the depth of clinical information needed to understand symptom-level variation within a disease. Integrated electronic health record data can provide access to routinely collected patient-reported outcomes, such as the Patient Heath Questionnaire-9 (PHQ-9) responses, which is a questionnaire assessing mental health symptoms across several domains. The integration of the PHQ-9 with clinical measurements like body mass index (BMI) and comorbidities creates an opportunity to move beyond diagnosis codes and evaluate how specific symptoms may relate to meaningful health outcomes.
To explore this question, we analyzed real-world clinical data from nearly 2 million encounters among adults with depression and/or anxiety who had documented BMI measurements and item-level responses to the PHQ-9 within the OMNY Health real-world data platform. Rather than focusing only on diagnosis-level measures, we examined PHQ-9 item 5, which captures appetite-related symptoms (“poor appetite or overeating”).
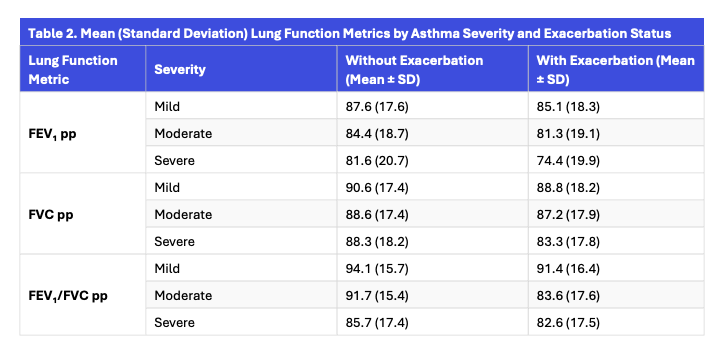
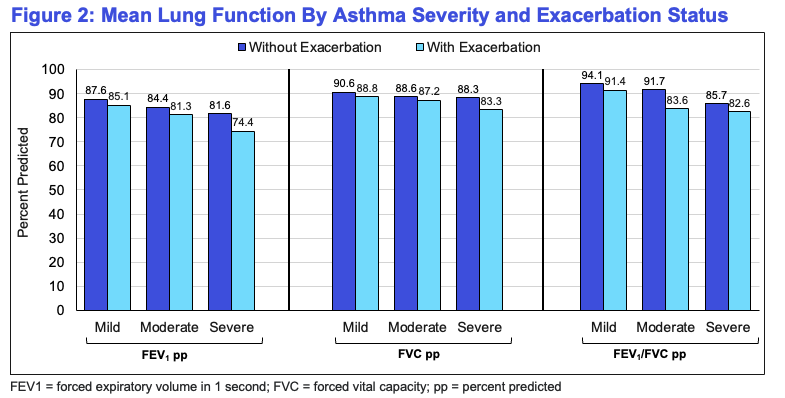
Our findings showed that appetite dysregulation was associated with meaningful differences in BMI outcomes. Higher severity of appetite-related symptoms was associated with increased likelihood of both underweight and severe obesity, suggesting that appetite-related symptoms may identify patients at risk for weight extremes.
Importantly, the relationship was not simply driven by obesity overall. The strongest pattern was observed for class II-III obesity, while class I obesity remained relatively stable across appetite symptom severity levels. This result suggests that symptom-level data may help identify patients with more clinically significant metabolic risk profiles.
These findings persisted even after accounting for demographic characteristics, antidepressant and antipsychotic use, and cardiometabolic comorbidities including diabetes, hypertension, and dyslipidemia.
A key takeaway is that routinely collected clinical information, such as PHQ-9 responses, when documented and accessible, can provide value beyond traditional diagnosis categories. Item-level patient-reported outcomes may offer scalable opportunities to better understand heterogeneity within populations and support more personalized approaches to care.
As real-world data continues to expand, leveraging the depth of information already captured in clinical workflows may help uncover new insights into disease patterns, patient risk, and opportunities for intervention.
——-
This work was presented as a podium presentation at the 2026 ISPOR Annual Meeting in Philadelphia, highlighting the value of rich real-world clinical data and patient-reported outcomes for generating actionable evidence.



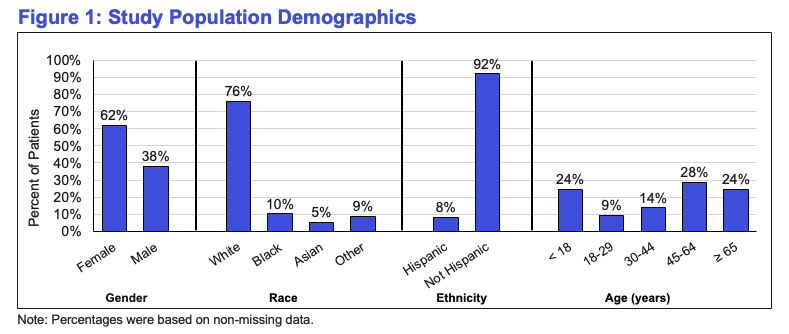







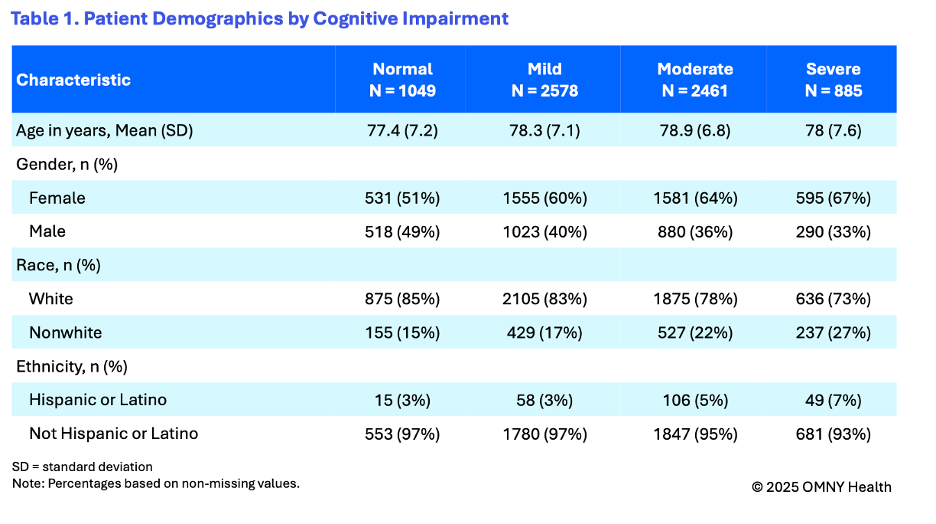
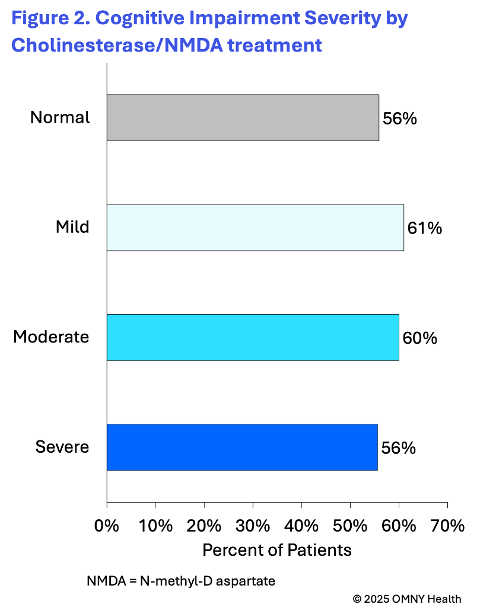
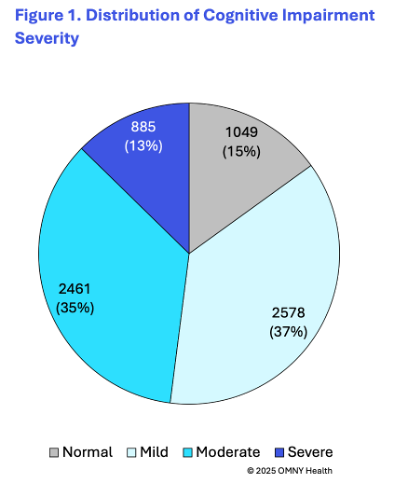 The findings provide insight into the cognitive state of patients as they are first observed within the health system and receiving a diagnosis of Alzheimer’s disease. On average patients were 78 years of age at the time of their first observed diagnosis. Following the first observed diagnosis of Alzheimer’s, patients were categorized into four groups based on their first reported cognitive scores: normal, mild, moderate, and severe.
The findings provide insight into the cognitive state of patients as they are first observed within the health system and receiving a diagnosis of Alzheimer’s disease. On average patients were 78 years of age at the time of their first observed diagnosis. Following the first observed diagnosis of Alzheimer’s, patients were categorized into four groups based on their first reported cognitive scores: normal, mild, moderate, and severe.